Department of Biosciences
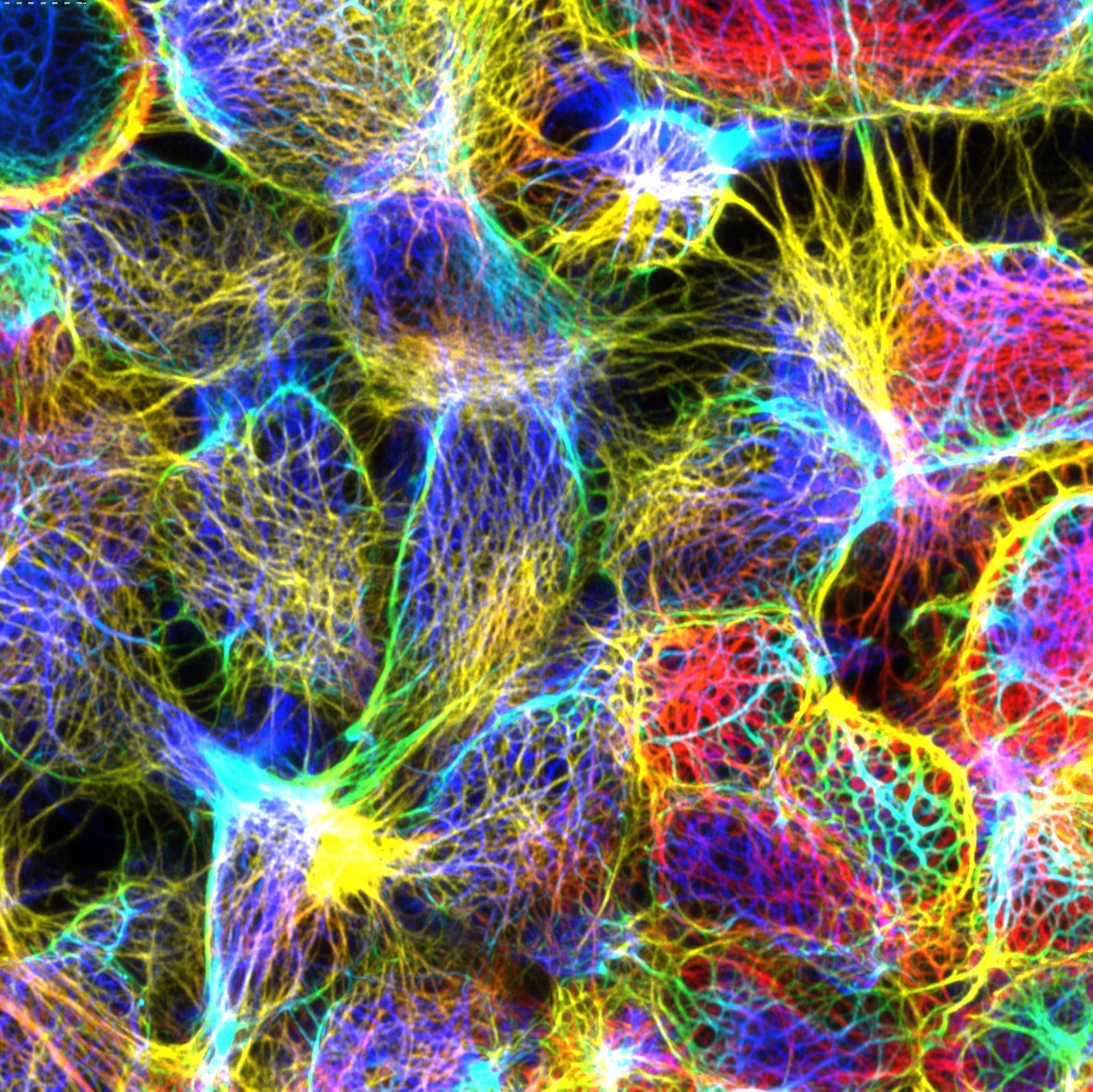

Welcome to the Department of Biosciences at Durham
Our research and teaching addresses fundamentally important questions facing humankind, from food security to sustainability in industrial processes, mechanisms of antimicrobial resistance and the impact of climate change on life on earth. Our students develop a wide range of analytical and practical skills that prepare them to meet these challenges.
Study with Us
-
Undergraduate Study
Our teaching is broad, from molecular structures to landscape-scale population dynamics, reflecting major questions in biology.

-
Postgraduate Study
Join a strong and vibrant postgraduate community for training in modern research techniques using state-of-the-art research infrastructure.
/prod01/prodbucket01/media/durham-university/departments-/computer-science/81569-1.jpg)
/prod01/prodbucket01/media/durham-university/departments-/biosciences/classroom/12257.jpg)
Undergraduate Study
Our teaching is broad, from molecular structures to landscape-scale population dynamics, reflecting major questions in biology.

Postgraduate Study
Join a strong and vibrant postgraduate community for training in modern research techniques using state-of-the-art research infrastructure.

Research
Discover more
/prod01/prodbucket01/media/durham-university/departments-/biosciences/infrastructure-/12479.jpg)
/prod01/prodbucket01/media/durham-university/departments-/biosciences/infrastructure-/12475.jpg)
/prod01/prodbucket01/media/durham-university/departments-/biosciences/12030.jpg)
/prod01/prodbucket01/media/durham-university/departments-/biosciences/infrastructure-/Crop-greenhouse.jpg)
News
-
Climate change driving rise in soil’s antibiotic resistance
A multinational research team, including Professor David W Graham from our top-rated Biosciences Department, have helped uncover a worrying new effect of climate change - the rise of antibiotic resistance in soil bacteria.Research news/prod01/prodbucket01/media/durham-university/central-news-and-events-images/news/Soil-bacteria-WEB.png)
-
Bacteria evolved to help neighbouring cells after death, new research reveals
Researchers have made the surprising discovery that a type of gut bacteria has evolved to use one of their enzymes to perform an important function after death.Research news/prod01/prodbucket01/media/durham-university/central-news-and-events-images/news/Bacteria-evolution-web-image.png)
-
Bioscientists achieve major advancement in protein-metal binding research
Researchers from our top-rated Biosciences department have made an exciting discovery that could revolutionise how scientists design and engineer biological systems.Research news/prod01/prodbucket01/media/durham-university/central-news-and-events-images/news/Protein-metalation-WEB.png)
Climate change driving rise in soil’s antibiotic resistance
A multinational research team, including Professor David W Graham from our top-rated Biosciences Department, have helped uncover a worrying new effect of climate change - the rise of antibiotic resistance in soil bacteria.

Bacteria evolved to help neighbouring cells after death, new research reveals
Bioscientists achieve major advancement in protein-metal binding research

Upcoming events
At Durham, we provide an outstanding environment for research and education in animal, plant and bacterial biology encompassing expertise from the atomic to whole ecosystem scale. Trained by Durham Biosciences in the skills and knowledge required, our students are able to succeed in a wide range of careers or training environments and help society tackle the challenges for the future.
Work with us
We welcome new members to our team, bringing new approaches to answering biological questions.
Questions about studying here?
Check out our list of FAQs or submit an enquiry form.
Your Durham prospectus
Order your personalised prospectus and College guide here.