We are delighted to maintain our position as one of the TOP 100 psychology departments in the world, a distinction we have proudly held since 2022.
The 2025 rankings assess over 55 subjects from over 5,200 institutions across the world, based on academic and employer reputation, citations per academic paper, impact and quality of research and international research collaboration factors.
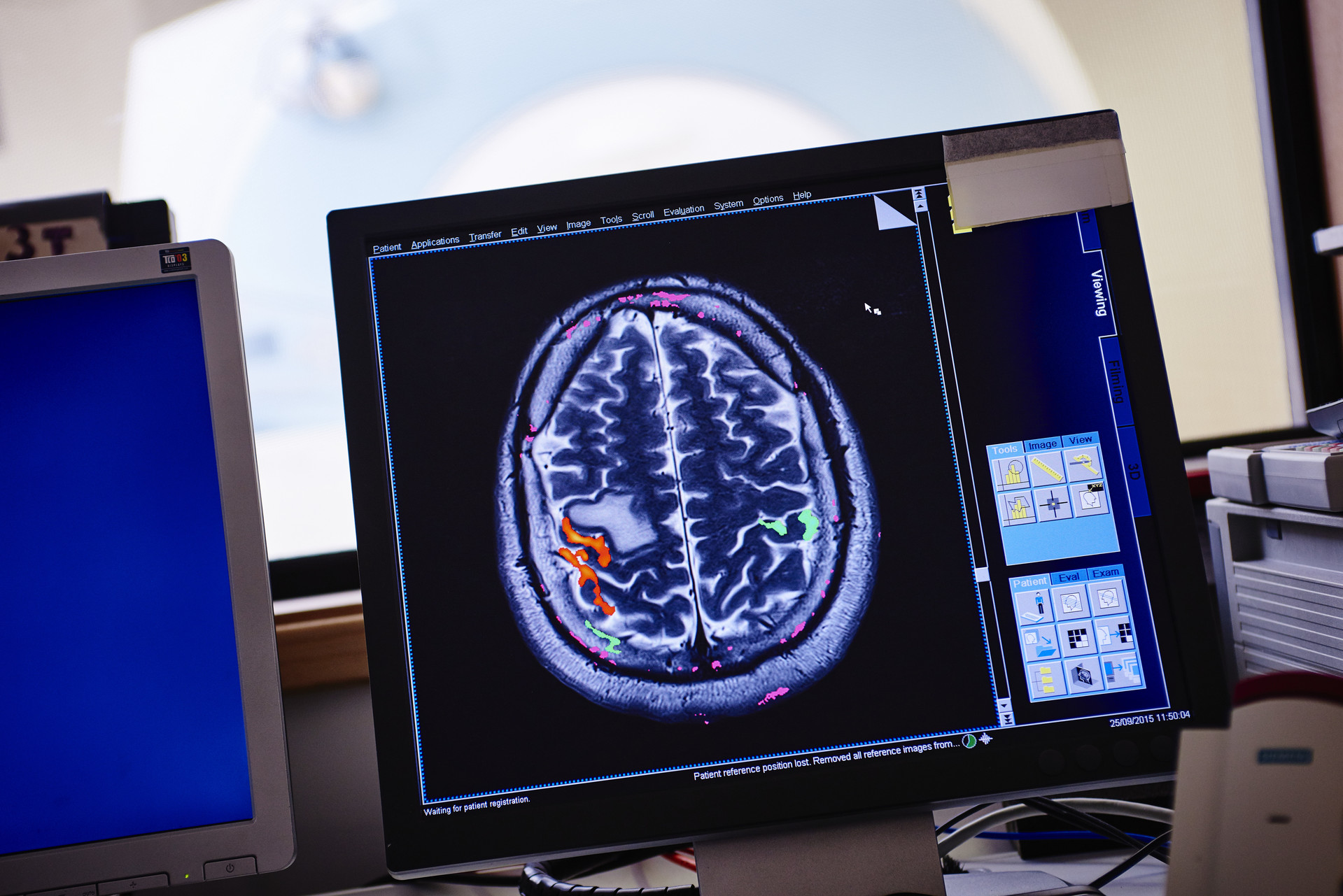
Recent research carried out by colleagues in our department includes work on fetal taste perception, promoting sustainable diets, children’s body image, and neuromodulation therapy for depression and much more.
Durham is a world-leading university. Our academic excellence and impact is reflected in our global rankings and this is a true credit to the outstanding teaching and research carried out at our University.
We're looking forward to helping you settle into student life and make the most of your experience. We encourage you to meet staff and familiarise yourself with the Department, by preparing as much as possible before your course begins
You will receive a genuinely research-led education. As well as learning the core principles of psychology, you will participate in research through seminars, conferences and research assistantship schemes. You will also have access to our world-leading clinical and experimental facilities, including motion capture, eye tracking and biophysical recording laboratories.
We offer both taught postgraduate and postgraduate research degree programmes. Our MSc programmes provide students with core skills, ideal for continuing on to complete a PhD, taking a research position, or entering the workplace. Our postgraduate students are supervised by academics with expertise in their fields and have the opportunity to engage with the local vibrant research community.
Chimpanzees have been observed copying quirky social behaviours from one another – wearing grass in their ears and bottoms – despite these actions offering no apparent practical benefit.
Congratulations to Professor Graham Towl who has been appointed the new Chair of a regional network of experts in prison and offender health and social care.
One of our department highlights is the dedicated laboratory space with equipment linked to teaching on our programmes.
At Durham we focus on you. We are energised teachers, who love our subject and want to share that passion with you.
Head of Department
'What I think makes Durham's Psychology course truly excellent is the contagious passion and excitement each of the staff have for Psychology.'
See what our staff and students get up to during their time at Durham University.
Durham University
Contact us to find out more about our courses and research. For current student enquiries please use "All other enquiries" button below
Durham University South Road Durham DH1 3LE
Phone: +44 (0) 191 334 3240
Fax: +44 (0) 191 334 3241
Check out our list of FAQs or submit an enquiry form.
Order your personalised prospectus and College guide here.